corpkit documentation¶
corpkit is a Python-based tool for doing more sophisticated corpus linguistics.
It does a lot of the usual things, like parsing, interrogating, concordancing and keywording, but also extends their potential significantly: you can create structured corpora with speaker ID labels, and easily restrict searches to individual speakers, subcorpora or groups of files.
You can interrogate parse trees, CoreNLP dependencies, lists of tokens or plain text for combinations of lexical and grammatical features. Results can be quickly edited, sorted and visualised in complex ways, saved and loaded within projects, or exported to formats that can be handled by other tools.
Concordancing is extended to allow the user to query and display grammatical features alongside tokens. Keywording can be restricted to certain word classes or positions within the clause. If your corpus contains multiple documents or subcorpora, you can identify keywords in each, compared to the corpus as a whole.
corpkit leverages Stanford CoreNLP, NLTK and pattern for the linguistic heavy lifting, and pandas and matplotlib for storing, editing and visualising interrogation results. Multiprocessing is available via joblib, and Python 2 and 3 are both supported.
Example
Here’s a basic workflow, using a corpus of news articles published between 1987 and 2014, structured like this:
./data/NYT:
├───1987
│ ├───NYT-1987-01-01-01.txt
│ ├───NYT-1987-01-02-01.txt
│ ...
│
├───1988
│ ├───NYT-1988-01-01-01.txt
│ ├───NYT-1988-01-02-01.txt
│ ...
...
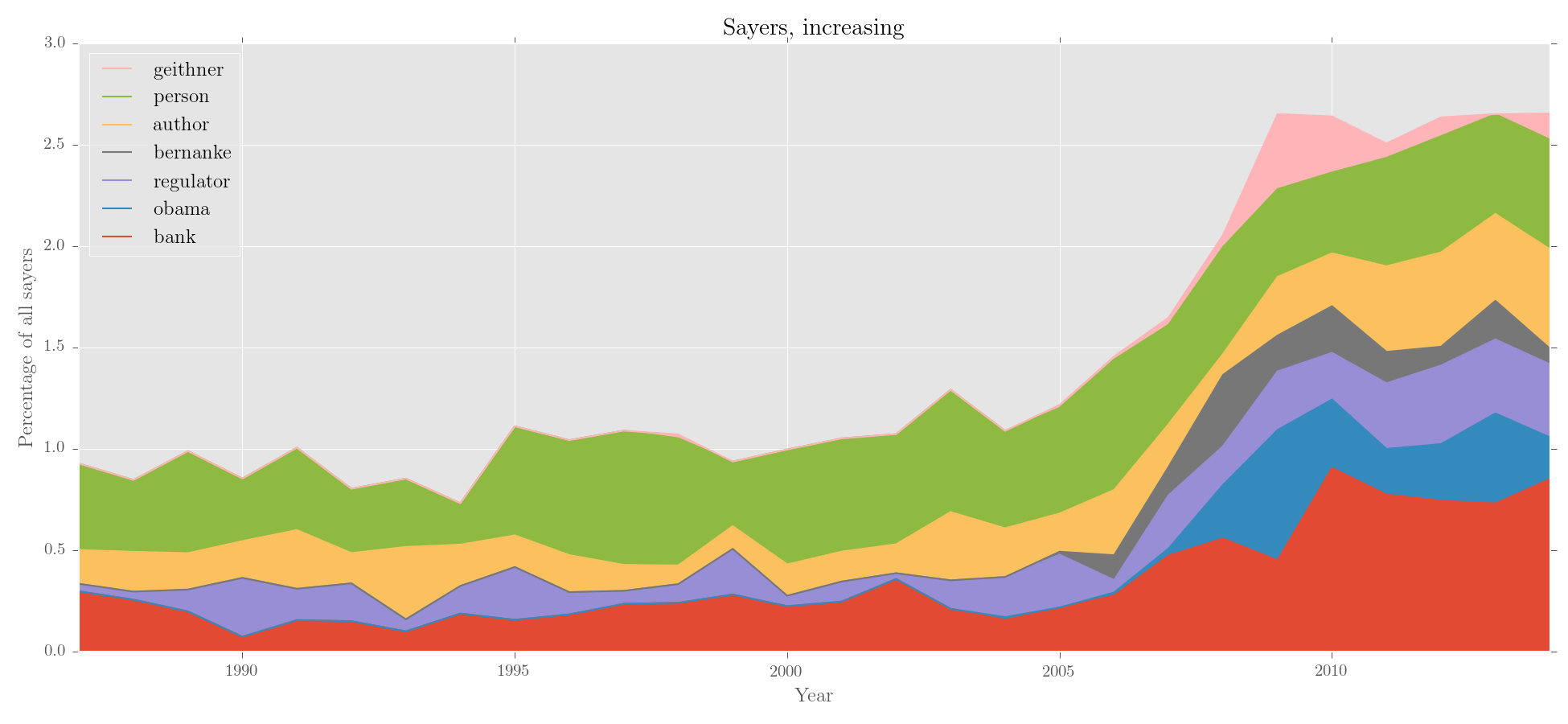
Below, this corpus is made into a Corpus object, parsed with Stanford CoreNLP, and interrogated for a lexicogrammatical feature. Absolute frequencies are turned into relative frequencies, and results sorted by trajectory. The edited data is then plotted.
>>> from corpkit import *
>>> from dictionaries import processes
### parse corpus of NYT articles containing annual subcorpora
>>> unparsed = Corpus('data/NYT')
>>> parsed = unparsed.parse()
### query: nominal nsubjs that have verbal process as governor lemma
>>> crit = {F: r'^nsubj$',
... GL: processes.verbal.lemmata,
... P: r'^N'}
### interrogate corpus, outputting lemma forms
>>> sayers = parsed.interrogate(crit, show=L)
>>> sayers.quickview(10)
0: official (n=4348)
1: expert (n=2057)
2: analyst (n=1369)
3: report (n=1103)
4: company (n=1070)
5: which (n=1043)
6: researcher (n=987)
7: study (n=901)
8: critic (n=826)
9: person (n=802)
### get relative frequency and sort by increasing
>>> rel_say = sayers.edit('%', SELF, sort_by='increase')
### plot via matplotlib, using tex if possible
>>> rel_say.visualise('Sayers, increasing', kind='area',
... y_label = 'Percentage of all sayers')
Output:
Installation
Via pip:
pip install corpkit
via Git:
git clone https://www.github.com/interrogator/corpkit
cd corpkit
python setup.py install
Parsing and interrogation of parse trees will also require Stanford CoreNLP. corpkit can download and install it for you automatically.
Graphical interface
Much of corpkit’s command line functionality is also available in the corpkit GUI. After installation, it can be started with:
python -m corpkit.gui
Alternatively, it’s available (alongside documentation) as a standalone OSX app here.
User guide¶
API documentation¶
Cite
If you’d like to cite corpkit, you can use:
McDonald, D. (2015). corpkit: a toolkit for corpus linguistics. Retrieved from
https://www.github.com/interrogator/corpkit. DOI: http://doi.org/10.5281/zenodo.28361